Wir verwandeln komplexe offene Geodaten in umsetzbare Erkenntnisse – mit einem besonderen Fokus auf humanitäre und klimabezogene Anwendungen. Mit langjähriger Erfahrung in Forschung und Entwicklung überbrücken wir die Kluft zwischen Technologie und praktischen Lösungen. Unsere maßgeschneiderten Werkzeuge und Prozesse nutzen fortschrittliche Methoden aus der räumlichen Datenanalyse und dem Deep Learning, um die spezifischen Anforderungen unserer Partner an Datenqualität und -anreicherung zu erfüllen.
Werkzeuge zur Messung der Vollständigkeit, Korrektheit und thematischen Genauigkeit von OpenStreetMap-Daten (OSM) weltweit.
Erweiterte OSM in analysierbaren Formaten, speziell auf verschiedene Bedürfnisse zugeschnitten.
Zusammenarbeit mit Behörden, internationalen Organisationen und Forschungseinrichtungen zur Weiterentwicklung von Methoden und Sicherstellung hoher Qualitätsstandards.
OpenStreetMap ist eine umfangreiche Quelle für nutzergenerierte, frei verfügbare Geodaten, die für viele Anwendungsbereiche genutzt werden können. Allerdings kann die Nutzung aufgrund fehlender standardisierter Datenerstellungsmethoden und unterschiedlicher Qualitätsanforderungen anspruchsvoll sein. Wir entwickeln Software und Dienste, mit denen OSM-Datenqualitätsindikatoren global oder für spezifische Gebiete berechnet werden können. So können Nutzende einschätzen, ob die Daten ihren Projektanforderungen entsprechen.
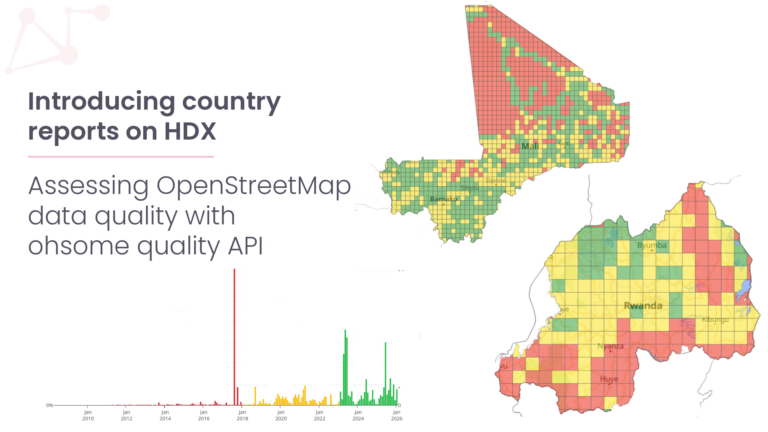
Das ohsome-Dashboard ermöglicht die Analyse von OSM-Daten mit vollständiger Versionshistorie – ganz ohne Programmierkenntnisse. Es erstellt Statistiken und visualisiert diese direkt im Dashboard. Dabei lassen sich Filter und Gruppierungen für Tags und Typen individuell anpassen, egal für welche Region oder welchen Zeitraum. Die ohsome Quality API (OQAPI) bietet Zugang zu Informationen zur Datenqualität von OSM für spezifische Regionen und Anwendungsfälle.
Neben der Softwareentwicklung konzentrieren wir uns auf die Anreicherung von OSM-Datensätzen, die in einem Data Lake gespeichert sind und den Nutzenden zugänglich gemacht werden. Die Qualität von OSM-Daten variiert aufgrund ihrer nutzergenerierten Natur, was die Arbeit mit großen Datensätzen besonders herausfordernd macht. Dies erschwert es, verlässliche Ergebnisse zu erzielen, vor allem für Forschende, die auf präzise und konsistente Daten angewiesen sind.
Diese Technologien helfen dabei, fehlende Attribute zu ergänzen und die Daten für die Nutzung vorzubereiten.
Wir liefern maßgeschneiderte, vollständige und erweiterte Datensätze, die auf die Bedürfnisse unserer Partner und deren Projekte abgestimmt sind.
Mit dem Zugang zu hochwertigen Datensätzen wird die Vorbereitungszeit verkürzt und die Genauigkeit von Modellen des maschinellen Lernens erhöht.
Das Road Surface Type Dataset bietet eine globale Sammlung von 2,2 Milliarden Bildern aus Mapillary, die Straßen entweder als befestigt oder unbefestigt kategorisieren. Der zweite liefert einen satellitengestützten Datensatz, abgeleitet aus hochauflösenden PlanetScope-Aufnahmen (2020–2024), der rund 9,2 Millionen Kilometer wichtiger Verkehrswege abdeckt und Informationen zu Oberflächentyp, Straßenbreite sowie einem „Humanitarian Passability Score“ enthält. Diese Datensätze unterstützen Anwendungen in wirtschaftlicher Entwicklung, ökologischer Nachhaltigkeit, Routenplanung und Katastrophenhilfe.

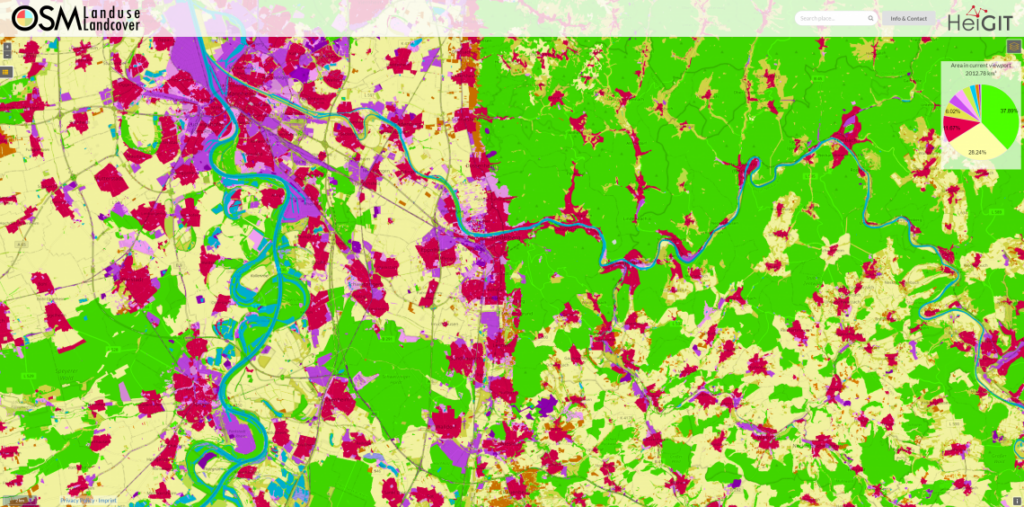
Die OSM Land Use Map ist eine Web-Anwendung, mit der globale Flächennutzungsmuster auf Grundlage von OSM-Daten angezeigt werden können. Klassifikationen von Flächennutzungsarten werden dargestellt, indem detaillierte Karten, die Informationen über das Vorkommen von Wohn-, Gewerbe-, und Industriegebieten während eines bestimmten Zeitpunktes enthalten, überlagert werden. Zusätzlich steht ein herunterladbarer Datensatz für die Offline-Analyse zur Verfügung.
Mit Hilfe unserer Dienstleistungen und Werkzeuge können OSM-Daten und ihre Veränderungen im Laufe der Zeit analysiert werden.
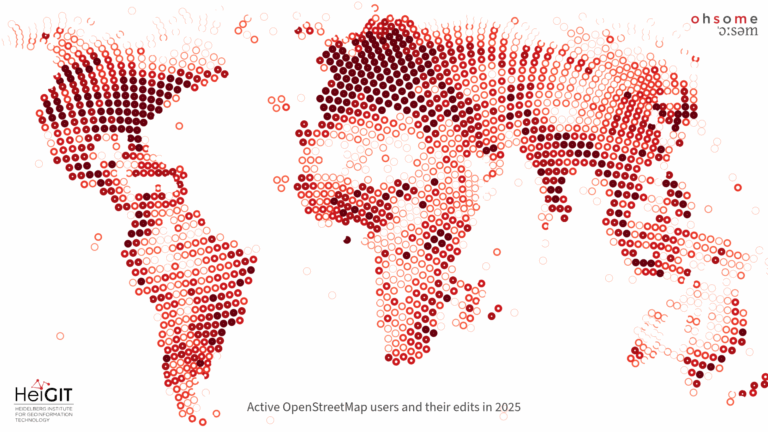
Globale Statistiken über Kartierungsaktivitäten in OSM werden mit ohsomeNow Stats nahezu in Echtzeit bereitgestellt. Dazu gehören die Anzahl der Mitwirkenden, Bearbeitungen der Karten, hinzugefügte Gebäude und die Länge von Straßen. Die Daten werden regelmäßig aktualisiert und können nach OSM-Changesets-Hashtags gefiltert werden. Das Dashboard wurde in Zusammenarbeit mit dem Humanitarian OpenStreetMap Team (HOT) entwickelt und ermöglicht den Zugriff auf Kartierungsstatistiken vom 21. April 2009 bis heute.