Nach dem wir letzte Woche das OSM Element Vectorisation Tool vorgestellt haben, wollen wir nun mögliche Anwendungsfälle und spezifische Beispiele für die Nutzung und Anwendung des Tools präsentieren. Dieser zweite von drei Anwendungsfällen (siehe Anwendungfall 1) vergleicht die Daten in den Regionen Maribor, Slowenien und Ngaoundéré, Kamerun. Beide Regionen werden in OSM exzeptionell gut mit Landnutzungs- und Landbedeckungsinformationen abgedeckt. Der Grund dafür ist ein Import, der in beiden Regionen auftrat: der RABA-KGZ-Import von offiziellen Daten in Slowenien und der Import von klassifizierten Satellitenbildern in Kamerun. Zumindest nehmen wir an, dass es sich bei zweitem um einen Import handelt. Leider unterlief es nicht dem gängigen Import-Prozedere und wurde nicht dokumentiert. Bitte besuchen Sie das repository für detaillierte Informationen.
Daten
Um diesen Anwendungsfall zu reproduzieren, laden Sie erst die beiden Beispiele maribor und ngaoudere herunter und konvertieren diese in ein GeoPackages (siehe README). Ansonsten, scrollen Sie weiter. Für eine Übersicht der exakten Implementation für verschiedene Datenaspekte, beziehen Sie sich bitte auf die Dokumentation.
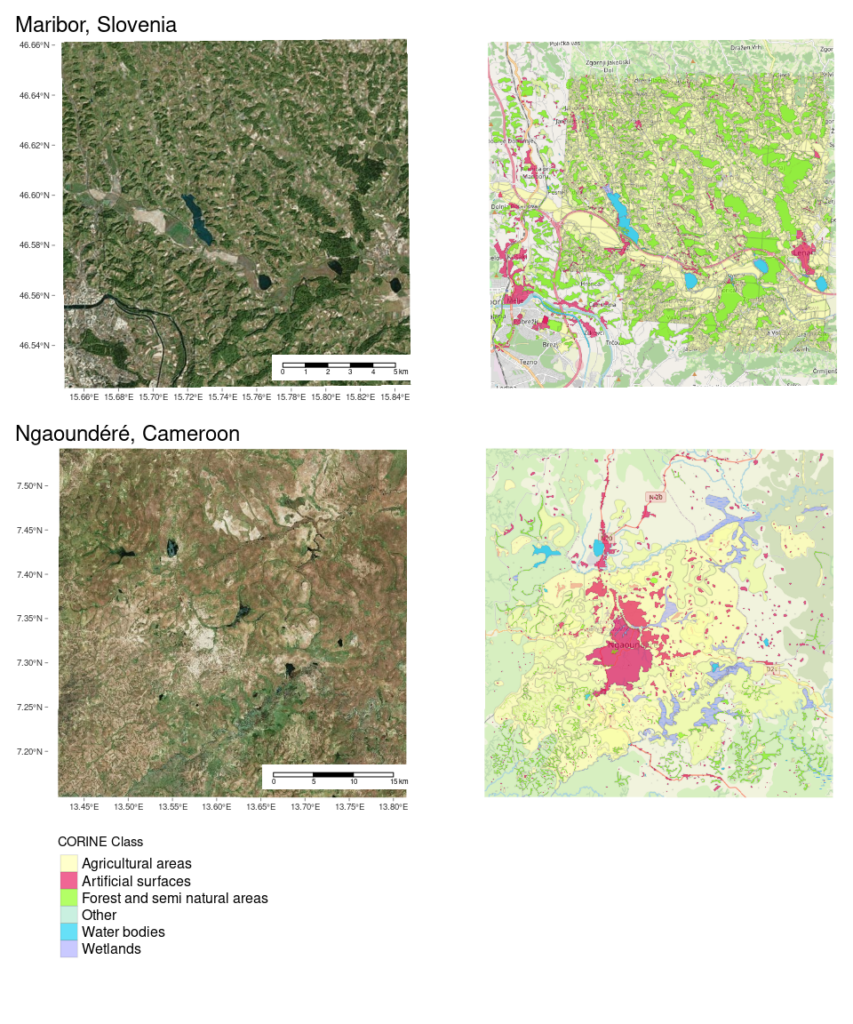
Die beiden Datensets repräsentieren einen Snapshot der Daten am 1. Januar 2022. Wir können sehen , dass die Daten in den beiden Regionen verschieden sind; Landschaftunterschiede, die eine Südeuropäische und eine Zentralafrikanische Region aufweisen (siehe Maßstabsbalken). Aber können wir dies so quantifizieren, dass eine Maschine dies ebenfalls versteht?
Analyse
Die beiden Regionen unterscheiden sich sowohl geografisch als auch in Bezug auf die Menge der OSM-Daten erheblich. Dennoch sind die Stichproben ausreichend groß, so dass ein Vergleich sinnvoll ist:
|
Region |
element_count |
|---|---|
|
Maribor |
13188 |
|
Ngaoundéré |
1736 |
Interessanterweise enthält das größere Gebiet von Ngaoundéré im Vergleich zu Maribor weniger Objekte, obwohl es einen „vergleichbaren“ Erfassungsbereich hat. Wir erwarten also automatisch größere Elemente in diesem Gebiet. Aber schauen wir uns die Zahlen an.
Statistiken
Mit Hilfe statistischer Tests kann untersucht werden, ob sich die beiden Datensätze signifikant unterscheiden.
Objekt Größe
Mal sehen, ob die Objekte in Kamerun deutlich größer sind als die in Slowenien:
##
## Wilcoxon rank sum test with continuity correction
##
## data: raw_indicator.obj_size by region
## W = 6113175, p-value <2e-16
## alternative hypothesis: true location shift is less than 0Es besteht ein hochsignifikanter Unterschied zwischen den beiden Regionen. Aber ist die Anwendung eins statistischen Tests hier das Richtige? Wenn wir Slowenien mit Kamerun vergleichen wollten, wäre es das, aber dann bräuchten wir eine irgendwie zufällige Stichprobe. Diese beiden Stichproben sind alles andere als zufällig. Stattdessen enthält die Stichprobe alle Elemente in willkürlichen Gebieten um Maribor und Ngaoundéré. Es handelt sich also eher um einen Vergleich zwischen diesen beiden Orten. In diesem Fall handelt es sich nicht mehr um eine Stichprobe, sondern um die Grundgesamtheit 1. Also lasst es uns anders angehen.
Visueller Vergleich
Geometrische Attribute
Zusätzlich zur Elementgröße werden wir weitere geometrische Attribute hinzufügen, um einen facettenreicheren Überblick über diesen Aspekt zu erhalten. Wir werden nämlich die Grobheit, die die mittlere Kantenlänge repräsentiert und die Komplexität, einen Indexwert, hinzufügen.

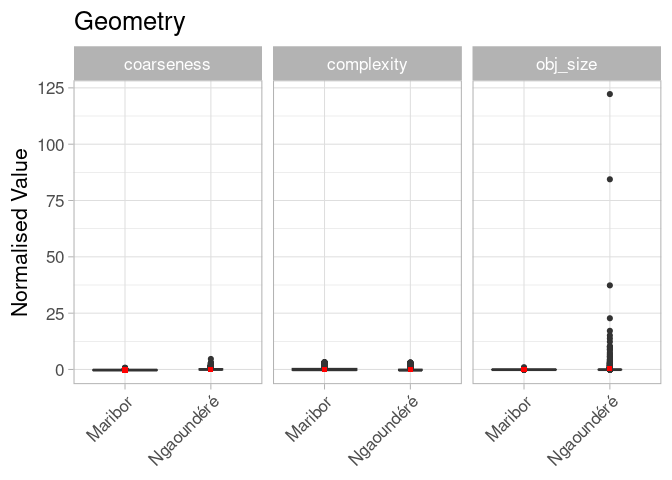
Diese Methode verlief nicht wie geplant. Wir haben nämlich die normalisierten Indikatoren verwendet, die das Tool zur Verfügung stellt. Das Problem ist, dass die Normalisierung (oder Skalierung) auf einer vordefinierten Menge von 1’000 zufälligen globalen Objekten stattfindet. Und das scheint in unserem Fall nicht gut zu passen. Was wir also sagen können, ist, dass es in Ngoundéré einige große Elemente gibt, sogar auf globaler Ebene. Werte zu haben, die unsere Elementattribute mit dem globalen OSM-Datensatz für Landnutzung und Landbedeckung in Beziehung setzen, ist zwar schön, aber wir bevorzugen lesbare Diagramme.
Wir können entweder die Daten neu skalieren oder die ursprünglichen/rohen Werte verwenden und akzeptieren, dass die y-Achse für die drei Variablen unterschiedliche Bereiche aufweist. Die Skalierung hat keine Auswirkungen auf die oben genannten statistischen Analysen, da diese mit Rängen arbeiten, die bei einer linearen Verschiebung der Daten auf eine neue Skala erhalten bleiben.
Lasst uns die Rohdaten versuchen, wir müssen nämlich unser Datenset nicht mit anderen Datensets vergleichen (noch nicht):

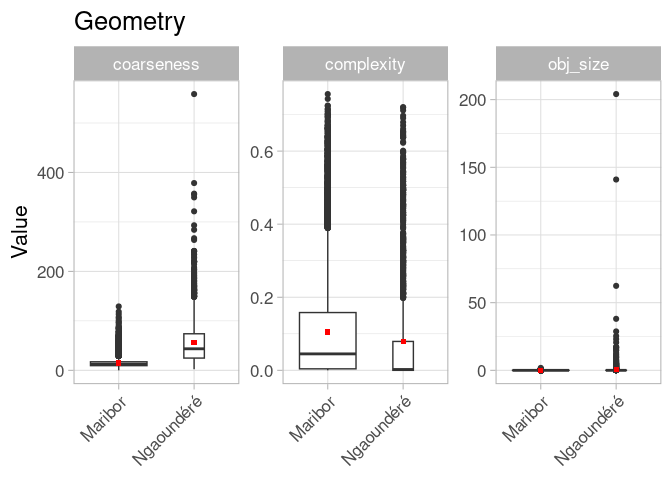
OK, besser, aber immer noch nicht sehr hilfreich. Ich denke, wir müssen die Achsen anpassen und die Extremwerte ignorieren, weil einige der Objekte einfach zu groß, zu komplex oder zu grob für die Darstellung sind.

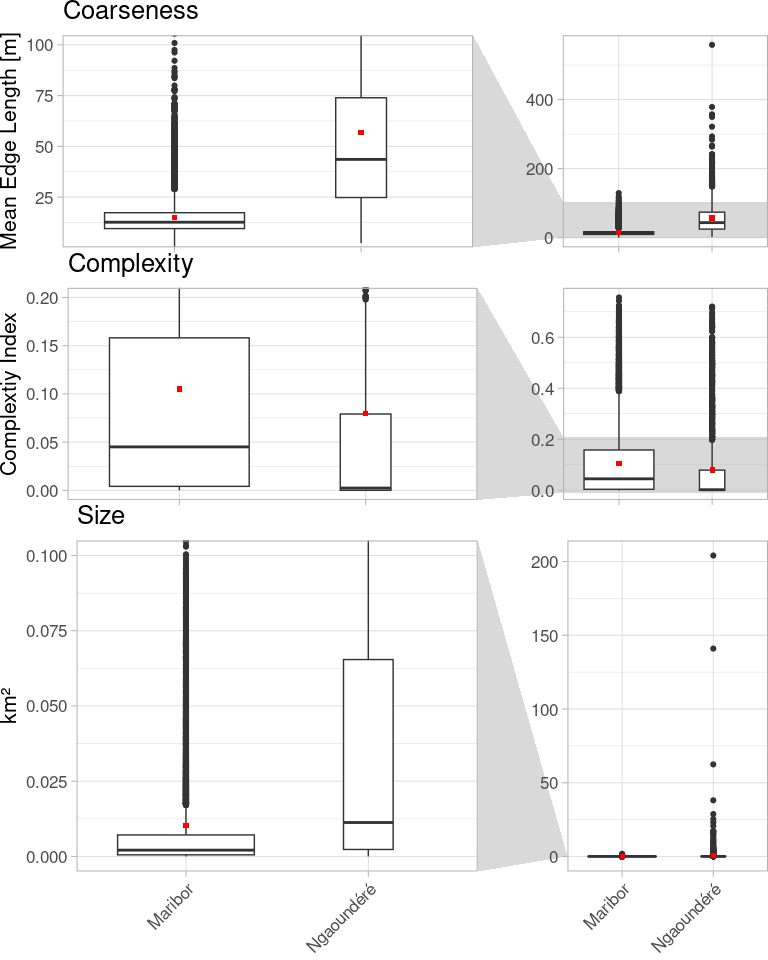
Endlich, großartig! Wir brauchen auch die Zahlen für eine fundierte Interpretation:
|
name |
median_Maribor |
mean_Maribor |
median_Ngaoundéré |
mean_Ngaoundéré |
|---|---|---|---|---|
|
coarseness |
12.621 |
14.860 |
43.569 |
56.887 |
|
complexity |
0.045 |
0.105 |
0.002 |
0.079 |
|
obj_size |
0.002 |
0.010 |
0.011 |
0.554 |
Bei der geometrischen Auswertung zeigt sich, dass die (wohlgemerkt: meist importierten) Polygone in Ngaoundéré im Allgemeinen größer, weniger detailliert gezeichnet und wahrscheinlich deshalb weniger komplex sind. Obwohl beide Regionen von kleinräumiger Landwirtschaft geprägt sind, scheint es, dass in Maribor diese Fragmentierung der Landschaft in OSM besser dargestellt ist.
Beitragende
Aber es gibt noch so viele andere Indikatoren, was ist mit den Kartierern dieser Objekte?
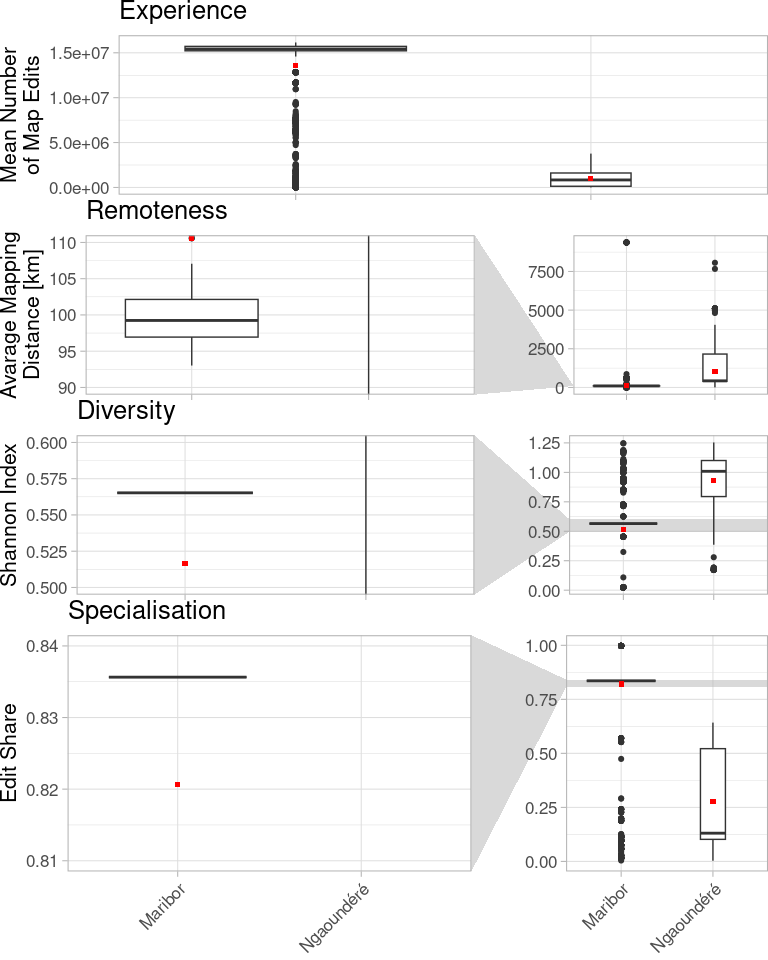
Die Regionen unterscheiden sich, aber nicht nur auf einer geometrischen Basis. In Zahlen:
|
name |
median_Maribor |
mean_Maribor |
median_Ngaoundéré |
mean_Ngaoundéré |
|---|---|---|---|---|
|
user_diversity |
0.565 |
0.516 |
1.009 |
0.931 |
|
user_mean_exp |
15423648.000 |
13624181.724 |
835810.500 |
970824.977 |
|
user_remoteness |
99.241 |
110.572 |
427.582 |
1013.249 |
|
user_specialisation |
0.836 |
0.821 |
0.131 |
0.276 |
Der Import wird in Maribor mit dieser hochspezialisierten, hochlokalen und hocherfahrenen (in der Definition der direkten Objektbearbeitungszahl) Nutzerbasis wirklich sichtbar. Aber die geringe Varianz in den Daten ist zweifelhaft. Es scheint, als hätte ein einziger Nutzer fast alle Daten in Maribor erstellt. Ein zusätzlicher Indikator könnte uns mehr Hinweise geben.
Community Größe
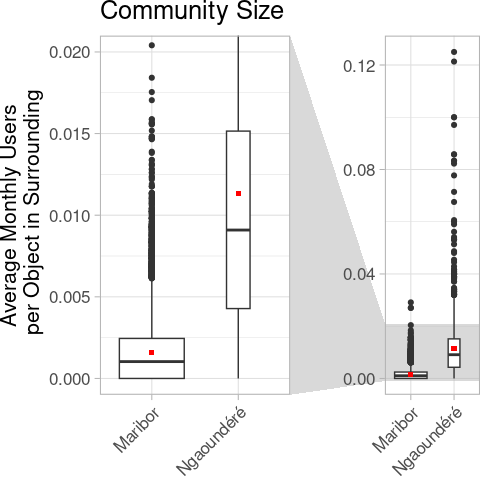
Und ja, wie erwartet ist die Community, ausgedrückt durch die Anzahl der Nutzenden pro Element in der Umgebung der analysierten Elemente, um eine Größenordnung kleiner.
|
name |
median_Maribor |
mean_Maribor |
median_Ngaoundéré |
mean_Ngaoundéré |
|---|---|---|---|---|
|
how_many_eyes |
0.001 |
0.002 |
0.009 |
0.011 |
Dies kann natürlich ein Artefakt der geringeren Objektgröße und damit einer höheren Anzahl von Objekten in der Umgebung sein. Ein Blick auf die Analysen der Mitwirkenden deutet jedoch in die gleiche Richtung. Tatsächlich wurden 78 % aller Bearbeitungen im Maribor-Datensatz durch das spezielle Importkonto gvil_import vorgenommen.
Mehr Daten!
Wie in Anwendungsfall 1 haben wir immer noch viele weitere Indikatoren:
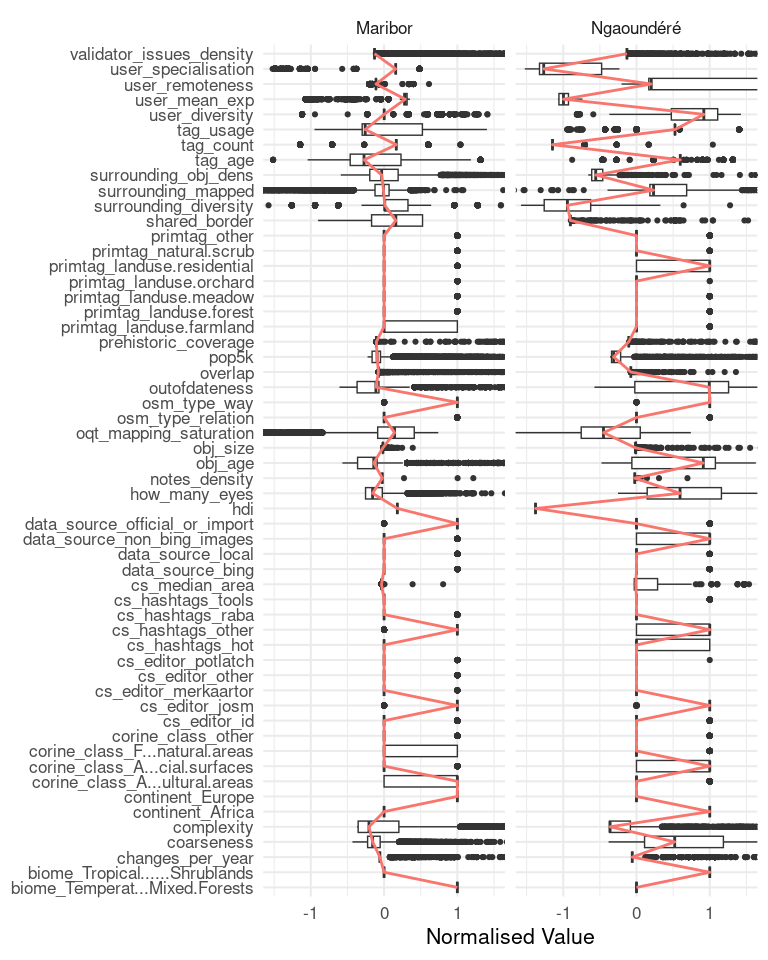
Einige dieser Daten sind eine Duplizierung von Daten, die wir bereits haben, und machen nur Sinn für einen globalen heterogenen Datensatz. Zum Beispiel die Lage von Maribor in Europa und Nagoundéré in Afrika. Aber auch andere Unterschiede können unser Interesse wecken. Zum Beispiel haben wir eingangs festgestellt, dass die Daten in Kamerun nur vermutlich von einem Import stammen. Tatsächlich werden bei einer Angabe der Datenquelle meist „maxar“ oder andere Satellitenbildanbieter genannt, so dass wir hier noch nicht beweisen können, dass ein Import aus anderen Quellen vorliegt. Beachten Sie auch den Unterschied im Alter der Objekte zwischen den beiden Datensätzen. Der Import in Ngoundéré scheint früher erfolgt zu sein (vor etwa sechs Jahren im Vergleich zu Maribor vor fast zwei Jahren).
Fazit und Ausblick
Das vorgestellte Beispiel kann ein guter Ausgangspunkt für weitere, speziellere Analysen sein. Die Rohdaten würden es beispielsweise ermöglichen, die Ergebnisse der zahlreichen Studien über die Auswirkungen von Einfuhren zu bestätigen oder zu widerlegen, z. B. Durch Witt et al., 2021 oder Juhász und Hochmair, 2018. Auch die Attribute bezüglich des Mapping-Prozesses, wie der verwendete Editor oder der Changeset-Bereich, werden für importierte und anderweitig beschaffte Daten sicherlich unterschiedlich sein. Für dieses Beispiel haben wir jedoch Belege für die Ergebnisse der Clustering-Analysen in unserem vorherigen Paper: Imports create a markable data structure2.
Die hier vorgestellte Analyse könnte auch aus einer anderen Perspektive genutzt werden: Da Importnutzer sowohl hinsichtlich der Anzahl der bearbeiteten Objekte als auch hinsichtlich des thematischen Bereichs der importierten Objekte herausragend sein dürften, könnten wir anhand der hier gezeigten Indikatoren (nicht angemeldete) Importe identifizieren.
1 In einer alternativen Untersuchung könnten wir natürlich zufällige Elemente aus einer Population auswählen und statistische Vergleiche anstellen, wie in diesem Artikel.
2 Um diese Behauptung wirklich zu beweisen, müssten wir natürlich weitere Analysen durchführen und die Daten aus ähnlichen Regionen mit und ohne importierte Daten vergleichen. Aber auch das ist ein Thema für ein anderes Mal.