Unlocking the Potential of Big Spatial Data for Practical Solutions
Overview
We specialize in converting complex open geo-datasets into actionable insights, with a particular emphasis on humanitarian and climate-related applications. Drawing from our experience in research and development, we bridge the gap between technology and real-world applications. Our custom-built tools and processes, incorporating advanced methods from spatial data mining and deep learning, are designed to meet specific data quality and enrichment needs of our partners.
Data Quality
Tools to measure completeness, correctness, and thematic accuracy of OpenStreetMap (OSM) data globally and in near real-time.
Enriched Datasets
Enriched OSM data in analysis-ready formats, tailored for data scientists.
Research
Collaborations with public sector, international organizations & research institutions to enhance methods and maintain high-quality standards.
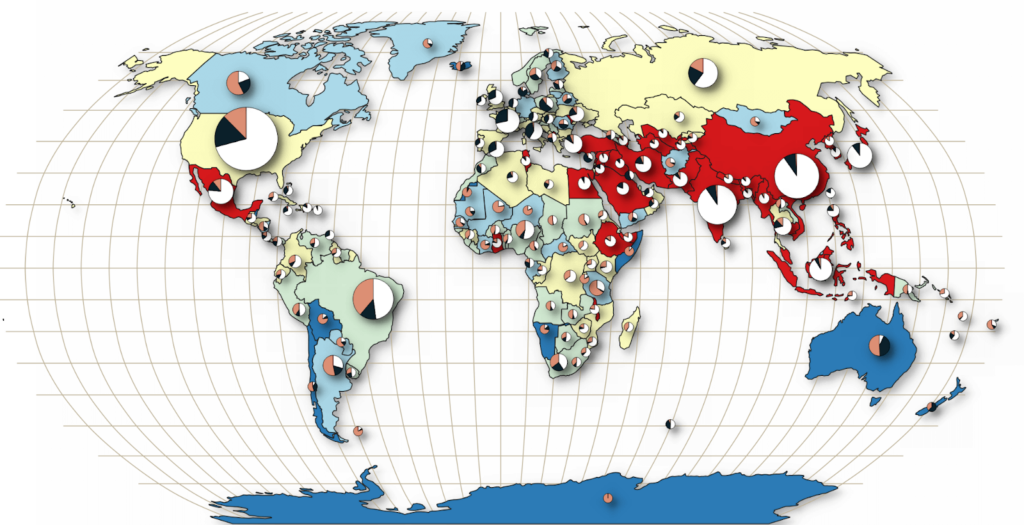
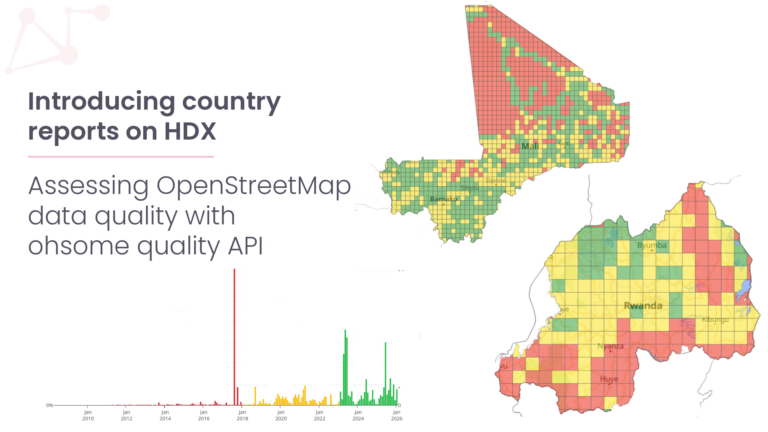
OpenStreetMap Data Quality Analysis
OpenStreetMap is a vast source for user generated free geodata for various use cases. However, due to the lack of standardized data generation methods and varying quality requirements, users may face challenges. We address this by developing software and services with which OSM data quality indicators can be calculated globally or for specific areas, helping users assess whether the data meets their project needs.
ohsome framework
For an in-depth overview of the tool, check out our video
The ohsome dashboard enables users to analyze OSM’s full-history data without programming skills. It generates accurate statistics and plots them directly in the dashboard, allowing for customizable filtering and grouping of tags and types across any region or time period. The ohsome quality API (OQAPI) provides access to OSM data quality information for specific regions and use-cases which might benefit i.e. humanitarian organizations and public administration.
Enriched Datasets
Beyond software development, we focus on enriching OSM datasets that are stored in a data lake accessible to users. Due to OSM’s crowdsourced nature, the data often varies in quality, posing challenges for researchers, especially those working with large datasets.
Key Features
AI and Machine Learning Integration
We use these technologies to add missing attributes, making the data ready-for-use.
Customized Datasets
We provide collaboration partners with data that’s complete, formatted, and enriched with attributes, depending on the project’s needs.
Improved Efficiency
Access to high-quality datasets reduces preparation time and increases the accuracy of machine learning models.
Road Surface Type Dataset
The first Road Surface Type offers a global dataset with 2.2 billion images from Mapillary and OSM data, categorizing roads as either paved or unpaved. The second one, provides satellite-based road surface dataset derived from high-resolution imagery (PlanetScope, 2020–2024), covering about 9.2 million kilometres of major transport routes, including surface type classification, road width, and a “Humanitarian Passability Score”. These datasets support applications in economic development, environmental sustainability, route planning, and emergency response.
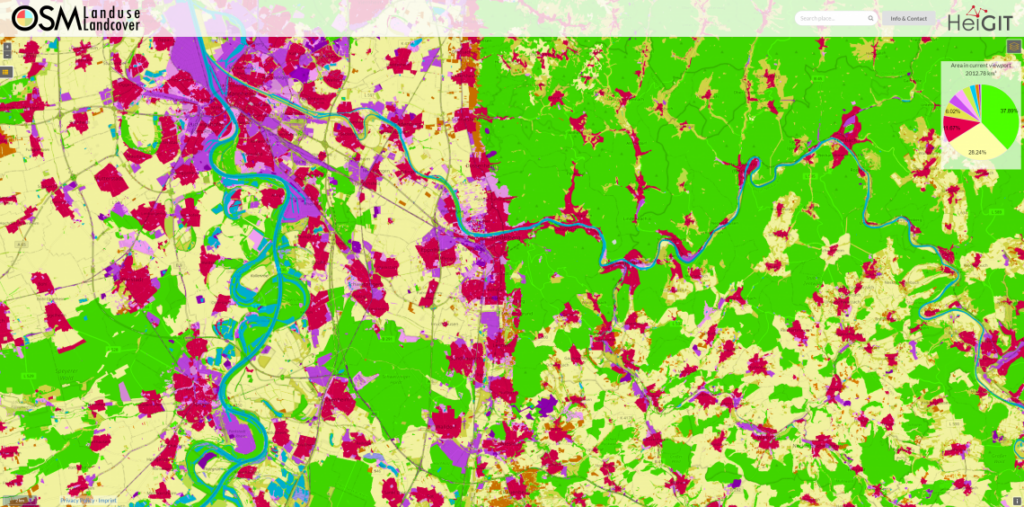
Land Use Land Cover
The OSM Land Use Land Cover Map web application offers a view of land use patterns globally, utilizing OSM data. This service visualizes land use classifications by integrating detailed maps with various land use categories, such as residential, commercial, and industrial areas for a single point in time. The application allows zooming for detailed views, making it a valuable tool for analyzing land use dynamics.
Real-time OpenStreetMap Data Insights
Our services and software help users analyze OSM data and its changes over time. They are primarily used by the OSM community, humanitarian organizations, and researchers seeking to gain insights from evolving geospatial data.
ohsomeNow Stats
For an in-depth overview of the tool, check out our video
The ohsomeNow Stats dashboard provides near real-time, global statistics on OSM mapping activity, including metrics like contributor count, map edits, added buildings, and road length. Data is updated in real time, with users able to filter by OSM Changeset hashtags and access statistics from April 21, 2009. This tool was developed in collaboration with the Humanitarian OpenStreetMap Team (HOT).